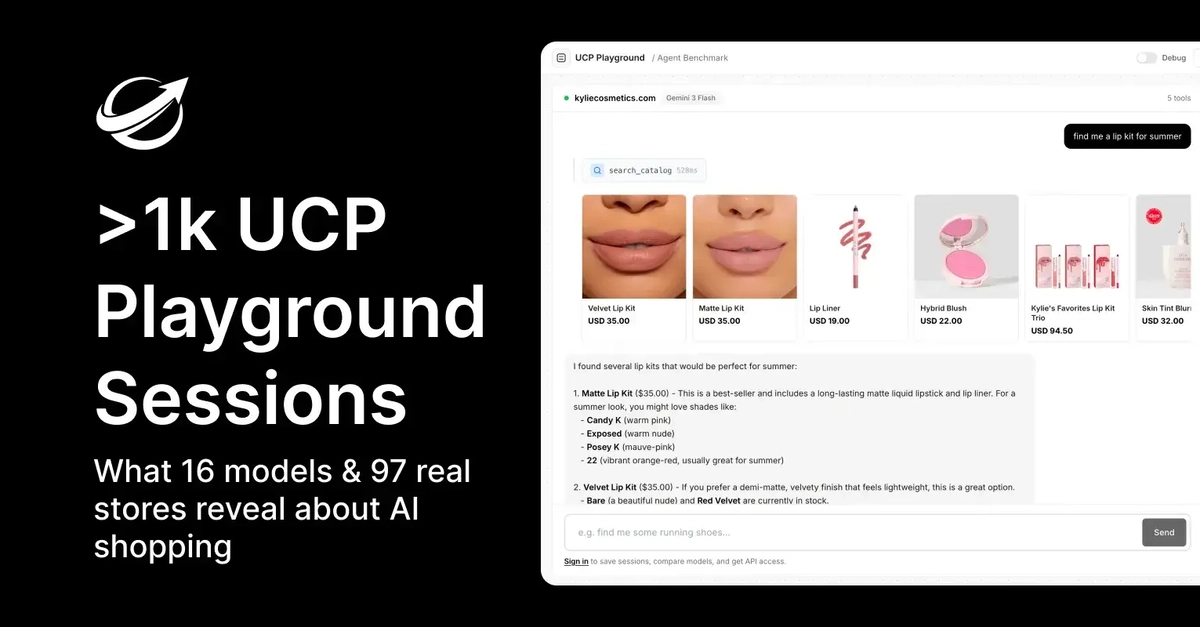
Речь не просто о более быстрой очереди на кассе; это фундаментальный сдвиг в цифровом взаимодействии. Когда AI способен ориентироваться в запутанных лабиринтах онлайн-торговли, от поиска краски нужного оттенка до оформления комплексного заказа из нескольких позиций, это означает глубокое изменение в том, как мы все будем взаимодействовать с цифровым рынком. Это не столько новое приложение, сколько новая операционная система для коммерции.
Всего восемьдесят дней назад тема AI-шопинга была лишь шепотом. Теперь же это громогласное заявление. Проект UCP Playground, посвященный стресс-тестированию этих зарождающихся AI-покупателей, выпустил бомбу данных: более 1000 сессий покупок, тщательно отслеженных на 16 передовых моделях и ошеломляющих 97 реальных магазинах. Это не просто набор цифр; это живой, местами хаотичный снимок текущих возможностей AI в одном из самых транзакционных уголков интернета.
Масштаб эксперимента
Цифры поражают. Мы говорим о более чем 1000 сквозных сессиях покупок, каждая с полным таймингом вызовов инструментов и воспроизводимыми потоками событий. Шестнадцать передовых моделей были подвергнуты испытаниям, представляющих собой тяжеловесов из каждой крупной AI-лаборатории. А поле боя? Разнообразная местность из 97 различных онлайн-магазинов, от гигантов на Shopify до кастомных e-commerce сайтов. Общая стоимость корзин, сформированных этими AI-агентами? Целых 96 032 доллара. Это набор данных, способный рассказать серьезную историю.
Кто на самом деле закрывает сделку?
А теперь к моменту истины: какие AI-модели действительно хороши в шопинге? Лидерборд, свежий из печи, рисует увлекательную картину. Claude Sonnet 4.5 сейчас возглавляет гонку с 50,8% успешных оформлений заказов, уверенно продвигаясь по солидной части датасета. Прямо за ним, почти вровень, идет Llama 3.3 70B с показателем 49,3%. Эти две модели не просто показывают хорошие результаты; они работают в совершенно иной лиге.
Но вот главный поворот, который заставляет прислушаться: GPT-5.2. Несмотря на свою хваленую мощь на всех мыслимых публичных бенчмарках, модель топчется в нижней трети с 23,6% успешных оформлений. Этот драматический разрыв между производительностью на бенчмарках и реальным успехом в шопинге — самая убедительная история, всплывающая из данных, и она заставляет задаться вопросом: почему такой разрыв?
Разрыв между производительностью на стандартных бенчмарках рассуждений и производительностью в транзакционных сценариях покупок — это самый большой дельта в нашей таблице лидеров.
Ловушка размышлений
Основная гипотеза, объясняющая этот шопинг-спад у некоторых из самых продвинутых моделей, сводится к фундаментальному несоответствию. Шопинг, как выясняется, не предполагает глубоких философских размышлений. Это о стремительном исполнении. Представьте: когда вы просматриваете товары онлайн, вы обычно не ведете с собой сократовский диалог о том, стоит ли добавлять носки в корзину. Вы их видите, кликаете, идете дальше. Эти транзакционные шаги по отдельности неглубоки, но следуют друг за другом с высокой скоростью.
Модели, разработанные для глубоких рассуждений, для взвешивания каждой нюансировки, тратят драгоценное время и токены на решения, не требующие такого самоанализа. Они переосмысливают. Они ставят под сомнение. И прежде чем вы успеете оглянуться, сессия истекает, виртуальная корзина остается забытой. Это как принести дотошно исследованную диссертацию на спид-дейтинг; подготовка похвальна, но ритм совершенно не тот.
Клуб отстающих
Не только GPT-5.2 испытывает трудности. Когорта моделей, специально дообученных для рассуждений — скажем, DeepSeek R1, o4-mini, Grok 3 Mini и QwQ 32B — стабильно находится внизу. QwQ 32B, в частности, не смог совершить ни одной завершенной покупки за время тестирования. Эта закономерность не нова; она просматривалась в более ранних, менее масштабных тестах и лишь укрепилась с взрывным ростом данных. Она применима к различным лабораториям и архитектурам. Вывод суров: те самые качества, которые делают некоторые AI-модели блестящими в решении сложных задач, по-видимому, мешают им в динамичном мире электронной коммерции.
Это не означает, что эти модели для рассуждений бесполезны для коммерции. Отнюдь. Они могут преуспевать в обработке спорных транзакций, навигации по сложным контрактным сценариям или решении крайних случаев, связанных с регулированием — задач, которые действительно требуют глубокого осмысления. Но для обыденного акта покупки чего-либо онлайн? Они приносят калькулятор на гонку квантовых компьютеров.
Взгляд в будущее
Что все это значит для нас, потребителей? Это означает, что эра AI-помощников для шопинга — это уже не научная фантастика. Она здесь, она функциональна и стремительно совершенствуется. В то время как одни модели еще только нащупывают свой путь, другие демонстрируют поразительную способность эффективно ориентироваться в цифровом пространстве. По мере созревания этих систем ожидайте персонализированный опыт покупок, проактивные рекомендации, которые действительно имеют смысл, и оптимизацию онлайн-покупок, которая может переопределить удобство. Базовая технология — это сдвиг платформы, сродни заре интернета. Последствия огромны.
FAQ
Заменят ли AI-боты для шопинга людей? AI-боты для шопинга разработаны для помощи и автоматизации транзакционных задач. Скорее всего, они будут дополнять человеческий опыт покупок, беря на себя рутинные покупки, поиск выгодных предложений и управление заказами, освобождая людей для более сложных или приятных аспектов шопинга.
Какая AI-модель на данный момент лучше всего подходит для онлайн-шопинга? На основе последних данных от UCP Playground, Claude Sonnet 4.5 и Llama 3.3 70B демонстрируют наивысший процент успешных оформлений заказов в сессиях AI-шопинга, что указывает на сильную производительность в транзакционных потоках.
Являются ли AI-модели, ориентированные на рассуждения, плохими для шопинга? AI-модели, ориентированные на рассуждения, могут быть медленнее в выполнении типичных задач шопинга, поскольку они склонны к более глубоким размышлениям на каждом этапе. Однако они могут лучше подходить для более сложных коммерческих сценариев, требующих детального анализа или принятия решений.



