Переворачиваем календарь на 17 августа 2026 года, и вместе с ним — фундаментальные изменения в работе облачных продуктов Atlassian: Jira, Confluence и других. Компания планирует начать сбор метаданных клиентов и контента из приложений для своих ИИ-решений, Rovo и Rovo Dev. Это не единичный случай; он следует по пятам за изменениями в политике GitHub в отношении использования данных Copilot. В совокупности эти шаги сигнализируют о явном сдвиге в отрасли к парадигме «отказ по умолчанию» (opt-out-by-default), что резко контрастирует с диаметрально противоположной позицией GitLab: никаких сборов данных, никаких тренировок ИИ на клиентских данных, никогда.
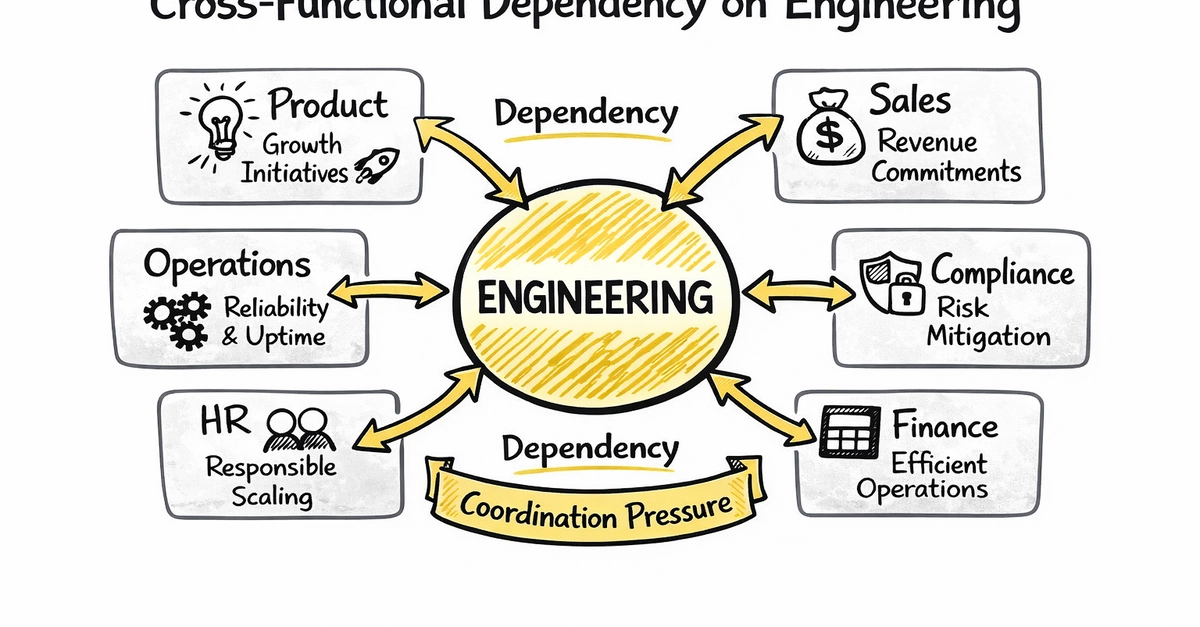
Для примерно 300 000 организаций, ныне обитающих в облачной экосистеме Atlassian, это объявление требует немедленного внимания. Последствия особенно остры для инженерных, IT- и программных менеджеров, которые полагаются на эти инструменты как на свою цифровую нервную систему. Это изменение приземляется с глухим стуком, особенно учитывая, что многие на этих ролях, вероятно, не были проконсультированы до принятия решения.
Хотя вопросы управления, связанные с практиками обработки данных как Atlassian, так и GitHub, перекликаются, масштабы риска данных значительно различаются. GitHub фокусировался в основном на исходном коде и взаимодействии разработчиков. Однако охват Atlassian простирается в самую ткань планирования и выполнения работы: дорожные карты проектов, внутренние вики, сложные конфигурации рабочих процессов и операционные следы, оставленные в Jira, Confluence и их связанных приложениях.
Что именно собирает Atlassian?
Atlassian разделяет сбор данных на две основные категории:
Метаданные: Сюда входят деидентифицированные операционные сигналы, такие как «story points», даты спринтов и значения SLA. Также сюда попадают данные из Teamwork Graph — по сути, карты взаимодействия ваших команд — и данные из любых сторонних приложений, которые вы подключили.
Контент из приложений: Это материалы, созданные пользователями. Представьте страницы Confluence, заголовки задач Jira, описания и те самые важные комментарии, которые часто содержат критический контекст.
Atlassian уверяет, что данные будут деидентифицированы и агрегированы перед использованием для обучения. Они заявляют, что собранные данные могут храниться до семи лет, при этом данные из приложений удаляются в течение 30 дней после запроса на отказ, а модели переобучаются в течение 90 дней. Однако есть конкретные исключения: клиенты, использующие ключи шифрования, управляемые клиентом, те, кто работает в Atlassian Government Cloud, Isolated Cloud, или с явными требованиями HIPAA, на данный момент освобождаются. Для подавляющего большинства облачных пользователей Atlassian сбор данных является стандартным — переключатель, который вы должны активно выключить, при условии, что можете позволить себе Enterprise-тариф.
Эта новая политика представляет собой явный отказ от предыдущих заверений Atlassian о том, что данные клиентов останутся неприкосновенными, недоступными для обучения ИИ или улучшения сервисов. Организации, которые выбрали Jira и Confluence именно за их способность управлять чувствительными рабочими процессами планирования, отслеживать ошибки, проводить постмортемы инцидентов и хранить внутреннюю документацию, теперь обнаруживают, что тот же контент предназначен для конвейера обучения ИИ Atlassian, всё это без явного согласия.
Тревожный рост «отказа по умолчанию»
Эта тенденция, когда поставщики переводят использование данных для обучения ИИ в режим «отказ по умолчанию», становится пугающе распространенной. Она неизменно возрождает одни и те же критические вопросы: как эта новая политика взаимодействует с существующими соглашениями об обработке данных (DPA)? Действительно ли интерпретация «метаданных» поставщиком соответствует тому, что ваши юридические и команды безопасности сочли бы нечувствительным? Для значительного числа организаций честным ответом на эти вопросы будет громкое «мы не знаем».
Когда поставщик в одностороннем порядке изменяет условия использования своих данных посредством обновления политики, вся ответственность ложится на клиента: обнаружить изменение, тщательно оценить его последствия и затем броситься действовать в рамках часто ограниченного периода времени. Это возлагает огромное бремя на и без того перегруженные IT- и юридические отделы.
Обязательный характер сбора метаданных во всех тарифах Free, Standard и Premium делает ситуацию особенно острой. Единственный практический путь к отступлению для тех, кто обеспокоен использованием данных для обучения ИИ, — это переход на тариф Enterprise. Это не мелкая правка; обычно это требует минимум 801 пользователя и индивидуального ценообразования, что является существенным финансовым скачком для многих команд. По сути, защита данных стала премиальной функцией, прямым следствием решений о покупке.
Этот многоуровневый подход также вводит более коварную проблему. Метаданные, такие как story points, метрики скорости спринта, показатели SLA и классификации задач, могут казаться безобидными в изоляции. Однако при агрегировании эти, казалось бы, безобидные точки данных рисуют удивительно детальную картину структур проектов, шаблонов производительности команд и общей динамики выполнения задач. Для организаций, работающих в конкурентных секторах, эта операционная аналитика бесценна, и «деидентифицированный» становится менее утешительным термином, когда закономерности так легко реконструируются в масштабе.
Когда Jira находится в центре операций организации — а так часто и бывает — она становится де-факто системой учёта для планирования, отслеживания и выполнения работы. Это единый источник истины для всего, от планирования спринтов и отслеживания ошибок до управления релизами и сложного межфункционального выполнения проектов. Для регулируемых отраслей, таких как финансовые услуги, государственный сектор или производство, Jira и Confluence могут содержать глубоко конфиденциальные операционные данные, подпадающие под строгие нормативные требования. Риски только усиливаются по мере того, как организации расширяют свою зависимость от более широкой экосистемы Atlassian, интегрируя Bitbucket, Bamboo и другие инструменты, тем самым увеличивая поверхность данных, питающих обучение ИИ.
И в этом суть: по мере размывания границ между функциями продукта и эксплуатацией данных ответственность за защиту интеллектуальной собственности вашей организации и операционных секретов теперь зависит от тщательного изучения контрактов и, для многих, от значительных финансовых вложений для доступа к базовым гарантиям конфиденциальности.
Когда поставщик меняет свою практику использования данных посредством обновления условий обслуживания, бремя ложится на клиента: заметить, оценить последствия и действовать в установленные поставщиком сроки.
Почему контроль над данными так важен?
Речь идет не просто о метриках тщеславия или абстрактном понятии конфиденциальности. Для многих компаний данные, хранящиеся в Jira и Confluence, представляют собой конкурентное преимущество, проприетарные процессы и конфиденциальное стратегическое планирование. Идея о том, что эта информация, даже будучи «деидентифицированной»,