The drone of a PagerDuty alert slicing through the predawn quiet is a sound no engineer ever wants to hear. It’s 3:03 AM, and the checkout service has apparently decided to take a personal day.
Look, I’ve been around the block a few times – twenty years in Silicon Valley will do that to you. And let me tell you, the pitch for “Agentic Engineering” sounds awfully familiar. It’s the same song and dance we’ve heard for years: technology will solve our problems, make our lives easier, and free us from the drudgery. This time, it’s AI. The promise? No more frantic 3 a.m. calls where you spend 30 minutes just figuring out what broke.
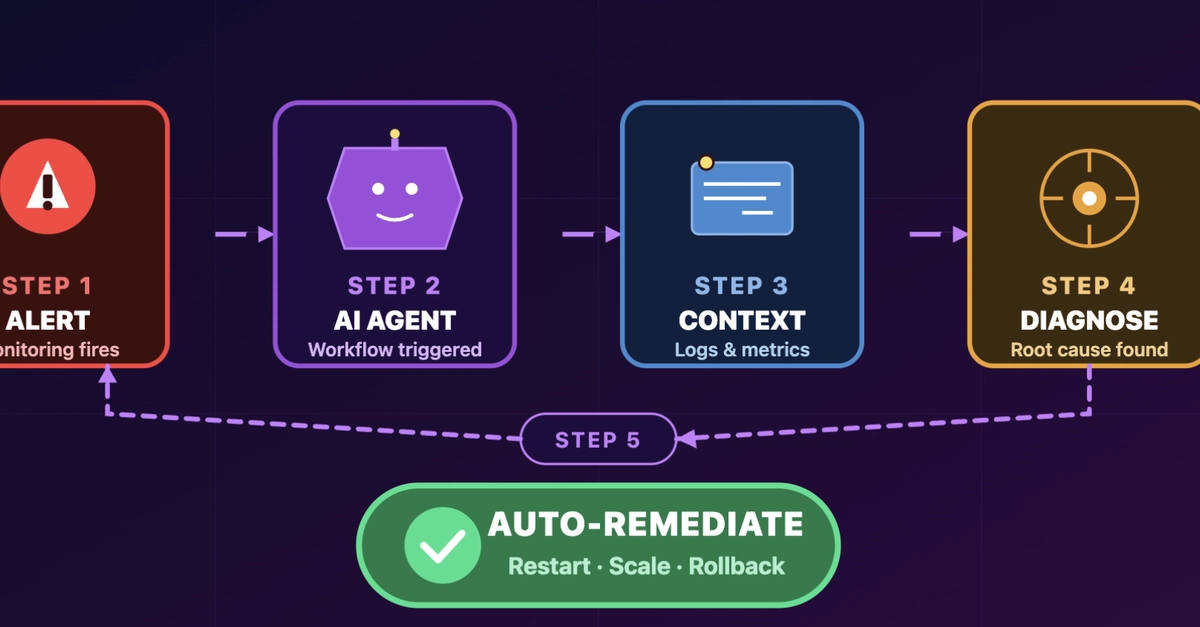
This whole concept, as laid out in the recent chatter around platforms like Port, hinges on this idea: the real problem with incident response isn’t necessarily troubleshooting, it’s the damn context. Your PagerDuty screams, but then you’re a digital archaeologist, digging through Datadog, GitHub, AWS, Slack, trying to assemble the scattered pieces of the puzzle before revenue takes a nosedive. It’s tedious, time-consuming toil.
The Operational Fragmentation Problem
Every team’s got its shiny tool – PagerDuty for alerts, Datadog for metrics, GitHub for code changes, AWS for infra, Slack for human communication. Individually, useful. Together, without some kind of digital conductor, it’s a cacophony. The author of this particular spiel is right about one thing: the current system forces engineers into repetitive, high-pressure tab-switching, copy-pasting, and guessing games. Who owns this service? Was it that last deployment? What the hell is happening?
Agentic Engineering, in this context, is pitched as the orchestrator. It’s not just slapping AI onto DevOps; it’s about feeding AI the right operational context. We’re talking about systems that don’t just summarize text but can actually act. Ingest alerts, understand affected services, correlate with deployments, find owners, pull runbooks, assess impact, propose fixes – all automatically. It’s a massive shift, moving from 30 minutes of frantic information gathering to a ready-made triage report.
So, Who’s Actually Profiting From This?
This is where my skepticism kicks in. The narrative is compelling: AI agents, armed with a central “context lake” of services, deployments, incidents, and owners, can now reason across disparate systems. Instead of isolated islands, they form a connected landscape. Port claims its platform maintains this live context, making AI outputs far more relevant than generic chatbot answers.
And the demonstration? Trigger an incident – “Checkout service returning 500 errors.” The workflow kicks off: fetch details, run AI triage, update the incident, send a formatted summary to Slack. The result? A structured report: title, urgency, priority, service, severity, business impact (30% order failure – ouch). It identifies potential downstream/upstream services and suggests next steps. This does sound efficient. It does save time.
But let’s be real. The real win here, for the companies selling these platforms, is the centralized control and data. They’re not just selling an AI agent; they’re selling the plumbing that ties all your existing, expensive tools together. They’re creating a dependency. And when things go wrong – and they will go wrong with any complex system, AI or not – who’s on the hook? The vendor? The AI? Or the poor engineer who’s still ultimately responsible?
Think about it: The AI proposes remediation. Who signs off? Who executes it? Humans still stay in control, yes, but this is a subtle shift towards pushing decision-making, or at least critical analysis, onto a black box. It’s efficient, no doubt. But efficiency often comes with a cost, and in this case, it might be a further abstraction from the systems we’re meant to understand and manage.
Is AI Incident Response Just More Toil?
This isn’t to say it’s useless. Far from it. For many teams drowning in alert noise and context-switching, this could be a genuine lifeline. The ability to instantly surface likely causes and affected parties can shave critical minutes, even hours, off incident resolution times. It’s about automating the grunt work of incident response, the repetitive tasks that drain engineers and introduce human error under pressure.
However, the underlying principle of Agentic Engineering – AI taking action within workflows – is where the real potential, and the real risk, lies. If the AI can query the catalog, send formatted results, and propose next steps, how long before it’s authorized to execute those steps? That’s the frontier. And frankly, it terrifies me a little. I’ve seen enough “innovations” that promised to simplify things only to create new layers of complexity and vendor lock-in.
So, does it save you from 3 a.m. calls? Potentially, by making the initial response faster and more informed. But does it fundamentally change the high-stakes nature of production incidents? Not yet. It automates the drudgery, yes. But the buck still stops with the humans.
And in Silicon Valley, the most valuable asset—and the biggest liability—is always the human. Who’s actually making money here? The platform providers, undoubtedly, by integrating and monetizing your existing toolchain. The engineers? They’re getting some of their time back, but they’re also gaining a new layer of abstraction and a reliance on yet another system.
What About the Future of Developer Work?
My prediction? Agentic Engineering will become a standard layer in DevOps tooling. Just like CI/CD is ubiquitous now, AI-driven incident response and workflow automation will be expected. It’s too efficient not to be adopted by some. But I suspect we’ll see the same pattern as with many other automation efforts: it reduces the frequency of certain problems, but when they do occur, they might be more novel, harder to debug, and still require that seasoned human intuition. The AI will be a powerful assistant, but I wouldn’t bet my entire career on it replacing the experienced engineer entirely. Not anytime soon, anyway.
🧬 Related Insights
- Read more: This Dev Gave His AI Manager One Brain Across Telegram, WhatsApp, Web, and Calls
- Read more: FOSS Force’s March 2026 Blockbusters: Kernel Extensions, Distro Rebellions, and a Browser That Doesn’t Spy
Frequently Asked Questions
What does an AI agent in incident response do?
An AI agent in incident response analyzes incoming alerts, gathers relevant context from various engineering tools (like metrics, logs, deployments, and infrastructure), identifies the affected service and its owners, assesses the business impact, and proposes potential remediation steps. It aims to automate the manual information-gathering and initial triage process.
Will AI incident response replace human engineers?
While AI incident response tools can automate many repetitive tasks and speed up initial diagnosis, they are unlikely to replace human engineers entirely in the near future. Complex incidents often require nuanced judgment, creative problem-solving, and a deep understanding of system architecture that AI currently lacks. Engineers will likely shift to overseeing AI, handling more complex escalations, and focusing on strategic improvements.
How much time can AI incident response save?
Reports and demonstrations suggest that AI incident response can save significant time, potentially reducing the initial 30 minutes of context gathering in an incident down to mere seconds. This allows engineers to focus on actual problem-solving and remediation much earlier in the incident lifecycle, leading to faster resolution and reduced downtime.



